Iedra reúne varios diccionarios: el DLE de la RAE, el Diccionario del español actual de Seco, Andrés y Ramos, y el María Moliner. Cada uno trocea el significado de una palabra a su manera: uno distingue cinco acepciones donde otro ve tres, las ordena al revés o aplica un nivel de detalle diferente. Hasta ahora convivían en la misma ficha, uno debajo del otro, sin hablarse entre sí. Lo que hemos hecho estos días es alinearlos por sentido: emparejar las acepciones de los tres que describen la misma idea, aunque cada diccionario la redacte a su modo.
De esa alineación salen tres cosas distintas, que es de lo que va este post: un bloque de «Sentidos» en la cabecera de cada ficha, una lista de palabras vecinas calculada por sentido, y un mapa de todo el vocabulario español. Vayamos por partes.
Un sentido, tres diccionarios
El mejor ejemplo es merengue. Si abres su ficha, lo primero que verás ahora es un resumen que cuenta cuántos sentidos tiene la palabra y cómo se reparten entre los tres diccionarios, y que se despliega en una lista. Cada entrada de esa lista es un sentido: no la acepción de un diccionario concreto, sino la idea común a la que los tres apuntan.
Lo que no verás es el texto de las definiciones. El DLE, el Seco y el Moliner tienen copyright, así que Iedra no reproduce sus acepciones: cada sentido aparece etiquetado de forma neutra como «Sentido 1», «Sentido 2»… Lo que sí ves de cada uno es de qué diccionarios procede y qué palabras tiene cerca, y resulta que con eso basta para identificarlo. Estos son, por ejemplo, seis de los sentidos de merengue —los nombro aquí para que se sigan, pero en la ficha van numerados—:
- El dulce de claras y azúcar — lo recogen los tres diccionarios.
- El baile caribeño y su música — los tres.
- El Real Madrid y lo madridista, coloquial — también los tres.
- Persona delicada, un alfeñique — está en el DLE y en el Moliner, pero no en el Seco.
- Lío, follón — coloquial en Argentina, Bolivia, Paraguay y Uruguay; DLE y Moliner.
- Un tocado marinero de la moda de 1935 — solo en el Seco.
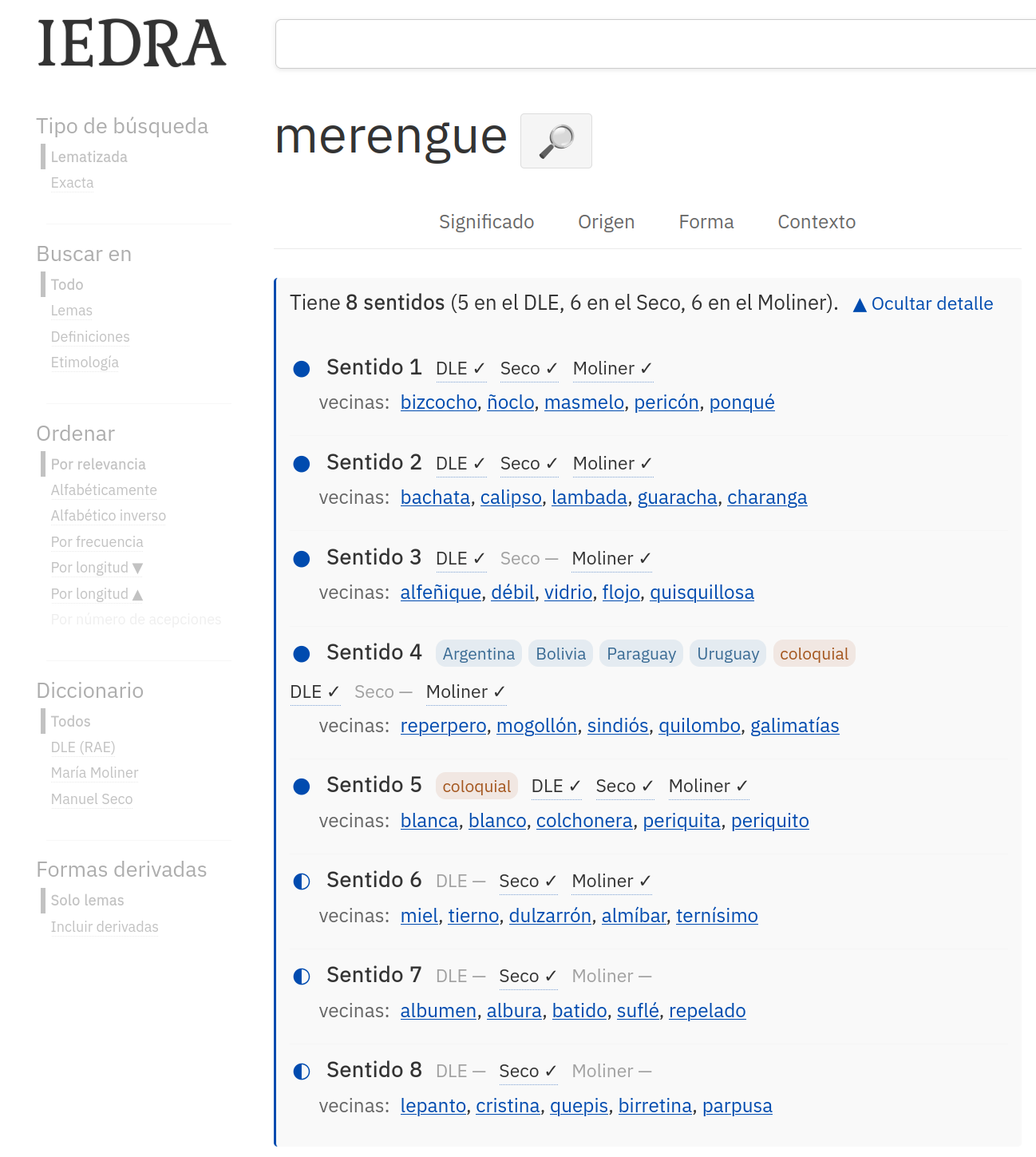 Los ocho sentidos de merengue: del dulce al Real Madrid, pasando por el follón rioplatense y un tocado marinero de 1935.
Los ocho sentidos de merengue: del dulce al Real Madrid, pasando por el follón rioplatense y un tocado marinero de 1935.
Cada sentido lleva tres etiquetas —DLE, Seco, Moliner— con un ✓ o un guion según lo recoja o no, de modo que se ve de un vistazo en qué coinciden y en qué se distinguen los tres. Un punto relleno (●), medio (◐) o vacío (○) indica además cuánta confianza tenemos en que el emparejamiento sea correcto, y si el sentido tiene alguna marca (geográfica, de disciplina, coloquial…) también aparece. Pero lo que de verdad te dice de qué va cada sentido son sus vecinas, que es lo siguiente.
El emparejamiento lo hace un modelo de lenguaje, leyendo las acepciones de los tres diccionarios y decidiendo cuáles hablan de lo mismo. Cubre las 85.430 palabras que aparecen en dos o más diccionarios (alineadas el 99,3%), y ha producido unos 141.000 sentidos compartidos, más unos 54.000 para las acepciones que solo recoge uno de los tres. Las palabras que solo aparecen en uno de los diccionarios también tienen su bloque de sentidos, aunque ahí no haya nada que emparejar. Clasificar y agrupar es justo lo que estos modelos hacen bien.
Las vecinas, por sentido
Bajo cada sentido aparece una lista de vecinas: palabras próximas en significado. Iedra tiene una sección parecida casi desde el principio —«palabras relacionadas»—, pero vivía al pie de la ficha, era una sola lista por palabra, y su utilidad oscilaba bastante. Ahora hay una por cada sentido, y, lo más importante, se calcula de otra manera.
La lista de siempre se sacaba contando coincidencias de vocabulario entre definiciones: dos palabras se parecían si sus definiciones compartían términos. La nueva compara lo que las acepciones significan. Cada acepción se convierte en una representación numérica de su contenido, y las vecinas son aquellas cuya representación queda más cerca. Dos palabras pueden no compartir ningún término en sus definiciones y aun así salir vecinas, si lo que describen es parecido.
La diferencia se ve enseguida comparando lo de antes con lo de ahora:
paz(sentido «ausencia de guerra»):- Antes:
diablesa, diabla, pacífico, cojón - Ahora:
orden, armisticio, calma, neutralismo, oliva, pacifismo, pacificación, sosiego
- Antes:
verdad(sentido «correspondencia entre concepto y cosa»):- Antes:
veras, mentira, boquifresco, amén, coña - Ahora:
certeza, verismo, idea, constancia, imagen, viveza, puntualidad, concepto
- Antes:
alipori(vergüenza ajena, palabra rara):- Antes:
cucharetear, vergüenza, encortar, lacha, empacho - Ahora:
lipori, achare, verecundia, vergoña, rubor, lacha, sofoco
- Antes:
Los fallos del método viejo eran de varios tipos. En paz, diablesa y cojón salían por accidente: alguna acepción compartía un término poco frecuente con esas entradas. En verdad lo más visible era mentira, una relación legítima, aunque se tratara de un antónimo. En alipori se mezclaban sinónimos buenos con ruido sin relación clara. La lista por significado es más sobria y más útil.
Sobre el modelo
Las vecinas —y el mapa que viene después— salen de un modelo de embeddings. A diferencia de los modelos de lenguaje tipo ChatGPT, que conversan, redactan y a veces inventan, un modelo de embeddings solo sabe hacer una cosa: leer un texto y convertirlo en esa representación numérica de la que hablábamos arriba, de modo que dos textos que significan algo parecido acaben con números parecidos. No genera nada; mide. Y se puede afinar: tomar uno ya entrenado y seguir educándolo con ejemplos del terreno que importa, en nuestro caso las definiciones de los diccionarios.
Hubo varias intentonas hasta dar con un buen afinamiento. Empezamos con un modelo pequeño y multilingüe, paraphrase-multilingual-MiniLM; se quedó corto. Saltamos a uno bastante mayor, multilingual-e5-large, y lo afinamos para el español de los diccionarios. Lo entrenamos con dos señales: los sinónimos que el propio DLE declara —65.000 acepciones con supervisión limpia y gratis— y la alineación entre diccionarios que acabábamos de construir, porque dos acepciones que tres diccionarios describen como el mismo sentido son, por definición, un ejemplo fortísimo de «esto significa lo mismo». Después vectorizamos con él las acepciones de los tres diccionarios, no solo las del DLE.
Por el camino probamos cosas que no cuajaron y descartamos: meter los antónimos como señal positiva (arrastraba esclavitud y sus derivados al lado de libertad), sumar los sinónimos del Moliner por separado (no aportó mejora alguna), cambiar a un modelo más moderno pero más pequeño (granite-embedding-311m, que perdió calidad). La configuración que ha quedado es la última que mejoró las cifras de forma medible, tras entrenar el modelo un par de horas en una GPU alquilada.
Un mapa de todo
Si cada acepción del diccionario es un punto en un espacio de significados, ese espacio se puede dibujar. Eso es el Atlas semántico: un mapa 2D con las 288.000 acepciones del DLE, el Seco y el Moliner repartidas según lo que quieren decir. Las que significan cosas parecidas se agrupan y forman continentes, penínsulas e islas; las que no tienen nada en común quedan lejos.
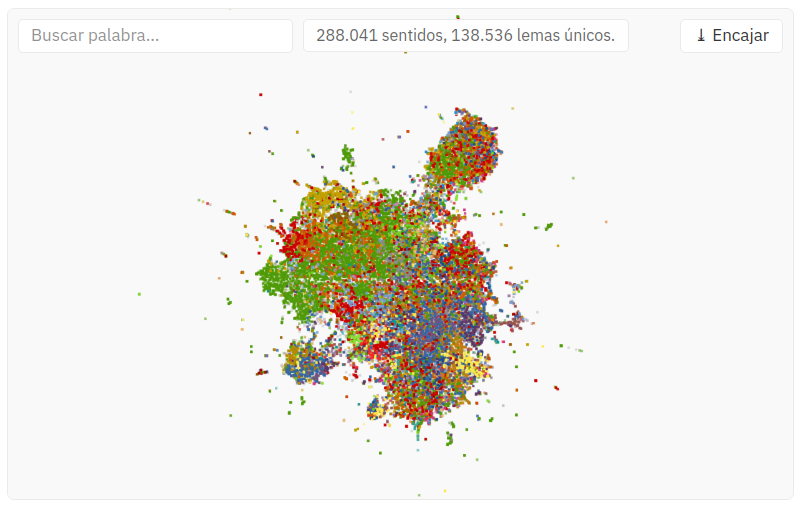
Como cada punto es un sentido y no una palabra entera, las palabras con varios significados aparecen repartidas por el mapa. Volvamos a merengue: el dulce se sitúa entre el alajú, el suspiro y el masmelo; el baile, entre la yenka, el bayón y el break dance; el madridista cae en una comarca de gentilicios y aficiones, junto a colchonera; el follón, entre el batifondo y la traca; y la persona delicada, entre alfeñique y encanijado. Todos esos «merengues» viven en zonas distintas del mapa, cada uno con su vecindario.
Para que el mapa se pueda leer de un vistazo y no sea solo una nube de 288.000 motas, el color de cada punto indica su tema —seres vivos, sentimientos, derecho, gastronomía…—: las regiones se reconocen por su color dominante antes incluso de acercarse a leer. Y gracias a la alineación, un sentido que comparten los tres diccionarios se dibuja como un solo punto, no como tres. Con una cautela: eso solo pasa cuando el emparejamiento es de confianza alta; los dudosos no se fusionan, y cada acepción conserva su punto. De ahí que el buscador del mapa cuente 10 sentidos para merengue donde la ficha resume 8: sus tres sentidos de confianza media van desplegados en las cinco acepciones que los componen.
Como todo lo que hace una máquina infiriendo significados, esto es aproximado: habrá emparejamientos discutibles, vecindades sorprendentes y algún desliz. Si veis algo claramente mal en alguna palabra, avisad.