Desde el último post grande se han ido acumulando pequeños cambios en la búsqueda y en la ficha de palabra. Recopilados:
Sugerencias al instante en el cajón de búsqueda
Desde hace años, el cajón de búsqueda sugiere palabras según vas escribiendo, pero hasta ahora el navegador tenía que consultar al servidor con cada pulsación: escribías una letra, esperabas la respuesta y aparecían las sugerencias. Con buena conexión no se notaba; con mala, llegaban a trompicones.
Ahora el navegador se descarga una sola vez —la primera vez que pinchas en la caja— un par de ficheros con casi 140.000 palabras del diccionario y sus formas (algo más de 2 MB en total, comprimidos), que se quedan guardados en la caché; a partir de ahí las sugerencias salen al instante, sin volver a pedir nada. De propina, tolera erratas: si escribes almuerso te sugiere almuerzo, y exhuberante te lleva a exuberante. Y si por lo que sea no llega a cargarse, el cajón sigue consultando al servidor como antes, así que nunca te quedas sin sugerencias.
 Cada sugerencia indica en qué diccionarios está la palabra; almorzar aparece porque almuerce —una de sus formas— empieza por lo tecleado.
Cada sugerencia indica en qué diccionarios está la palabra; almorzar aparece porque almuerce —una de sus formas— empieza por lo tecleado.
Una vista previa de las familias lingüísticas en /lenguas
La página de /lenguas lista los 244 idiomas detectados en las etimologías del DLE, agrupados por familia (latín, griego, árabe, lenguas amerindias…). Hasta ahora era una lista larguísima dominada por el latín. Ahora la cabecera enseña, antes de la lista, un treemap con la distribución por familia.
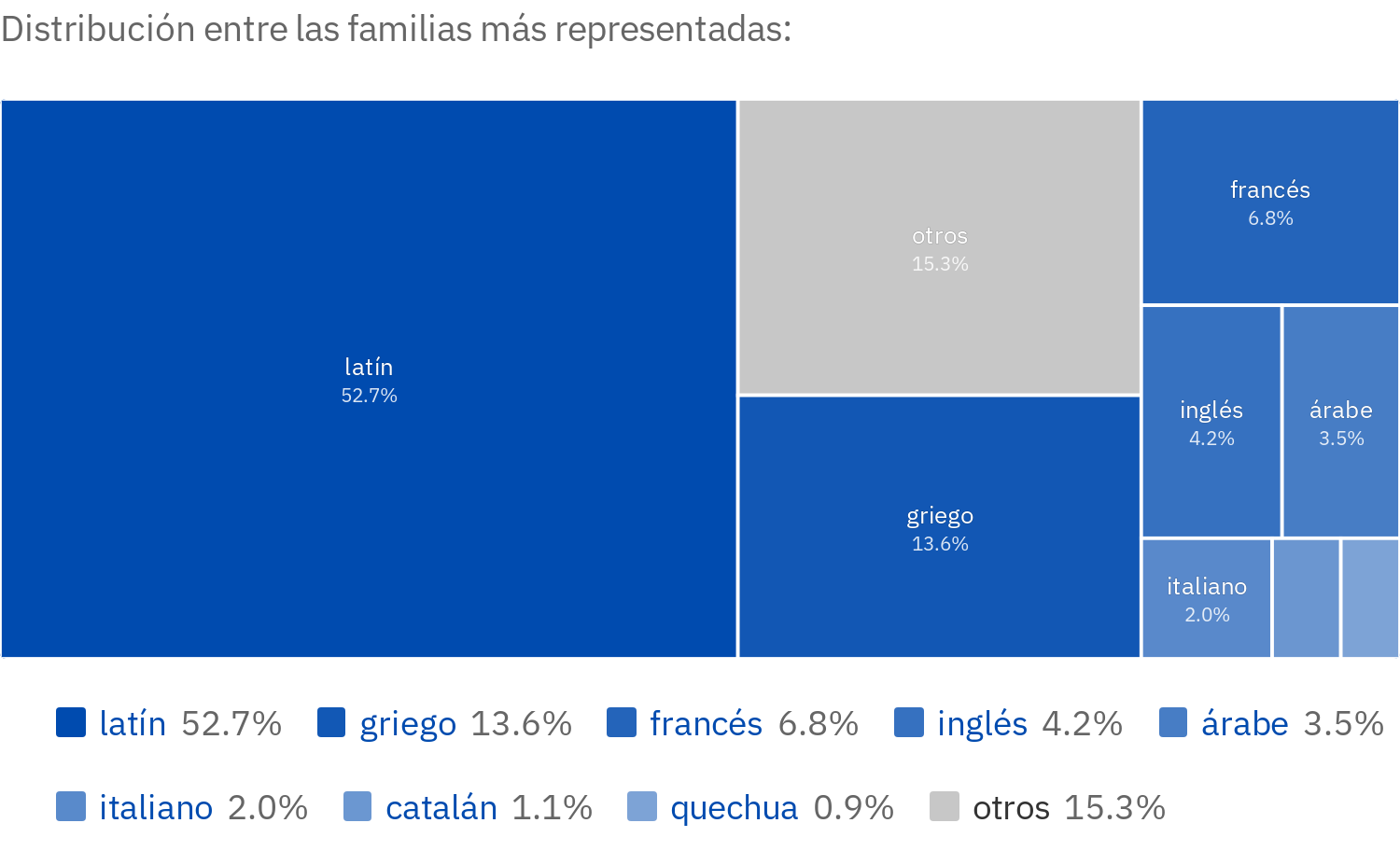
El latín se come más de la mitad. Lo demás: griego (13,6%), francés (6,8%), inglés (4,2%), árabe (3,5%), italiano (2,0%), catalán (1,1%), quechua (0,9%) y un cajón de «otros» (15,2%) que reúne las 230 lenguas restantes.
Antes el listado mezclaba categorías agregadas —«latín», entendido como agregado de latín tardío, latín medieval, latín vulgar…— con sus variantes individuales, y los recuentos no cuadraban. Ahora el grupo agregado se trata aparte: aparece como cabecera del bloque y solo cuenta cada palabra una vez aunque venga de varias variantes del mismo idioma. Y en la ficha de palabra, los nombres de idioma que aparecen en el texto de la etimología enlazan ahora a la búsqueda de las palabras llegadas de ese idioma.
Filtros más visibles y eliminables de un clic
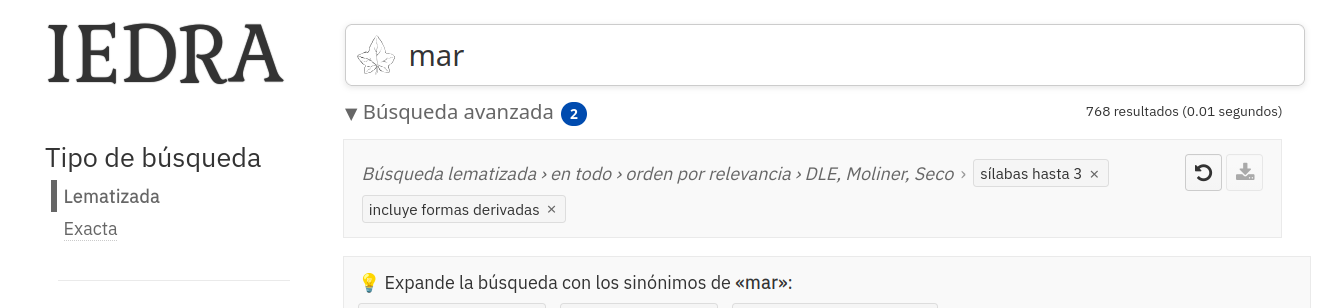
La búsqueda tenía un pequeño problema: con varios filtros aplicados, no quedaba claro de un vistazo cuáles estaban activos, y para quitar uno había que volver al panel avanzado. Ahora los filtros activos aparecen como etiquetas debajo de la caja de búsqueda, cada una con su × para quitarla de un clic, y el panel avanzado lleva en su título una insignia con el número de filtros activos.
Otros pequeños cambios en la zona de búsqueda:
- Hay un nuevo toggle «Incluir conjugaciones e inflexiones»: al activarlo, una búsqueda como amar devuelve también amaba, amaríamos, amando… La descarga de listado se desactiva cuando este toggle está activo, porque el listado puede salir enorme y mezcla lemas con formas derivadas (y eso pondría una barbaridad de palabras en cualquier rosco hecho a partir de la búsqueda).
- En el descriptor de la búsqueda actual (esa línea bajo el panel avanzado: «Búsqueda lematizada · en todo · orden por relevancia · DLE, Moliner, Seco») se muestran ahora también los filtros activos, y así el metatítulo de la página queda más informativo cuando alguien la comparte por enlace.
Selector de marcas lexicográficas con buscador
El DLE tiene alrededor de mil marcas distintas (geográficas, gramaticales, de disciplina, de uso…), y antes el filtro era un menú gigante imposible de navegar. Ahora el panel avanzado tiene un campo de texto: se escribe parte de la marca y aparecen las que encajan.
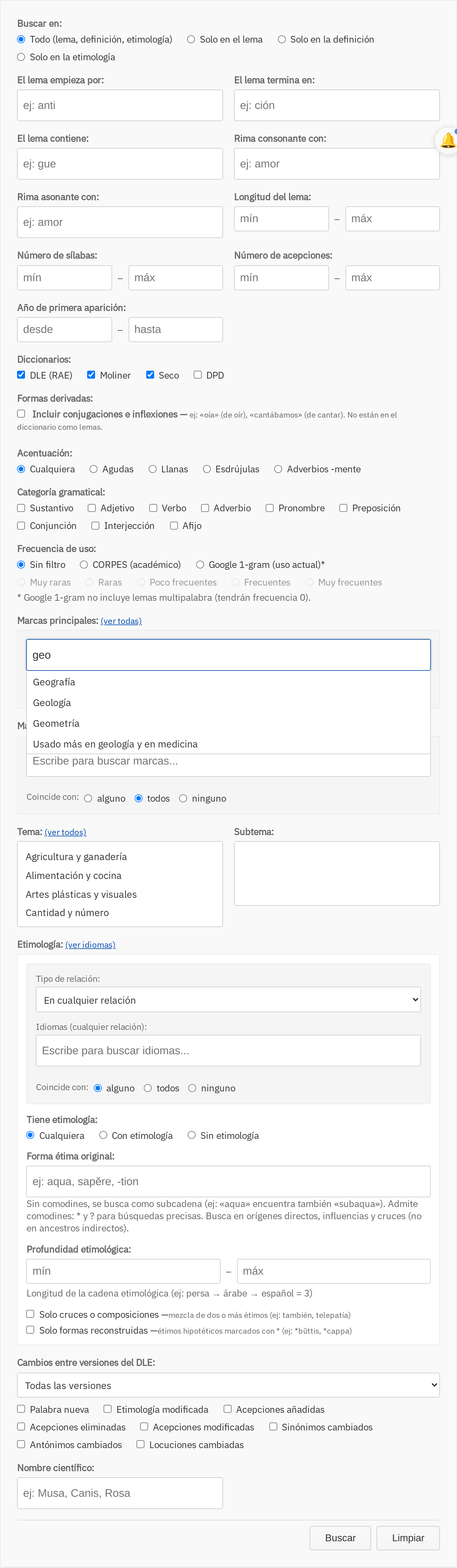
El selector se usa para tres tipos de filtro: marcas principales (gramaticales y de uso), marcas secundarias (de locuciones y combinaciones) y lengua de origen en la etimología. Cada uno tiene además tres modos de coincidencia para combinar varias marcas a la vez:
- Alguna: la palabra tiene al menos una de las marcas seleccionadas.
- Todas: la palabra tiene todas las marcas a la vez.
- Ninguna: la palabra no tiene ninguna de las marcas (negación).
Esto último abre filtros que antes no se podían expresar: «adjetivos que no sean despectivos», «palabras de origen latino excluyendo latín tardío y latín vulgar».
Por qué aparece cada resultado
Filtrar en modo «Alguna» tenía una pega silenciosa. Si pedías palabras de la marca Acústica o Astrología, los resultados salían mezclados sin decir cuál de las dos cumplía cada uno. Y con las marcas de locuciones era peor: filtrabas por Andalucía o Agricultura, te aparecía almanta, y para descubrir qué locución lo metía en la lista había que abrir su ficha y rebuscar entre todas.
Ahora cada resultado lleva debajo una pista de por qué está ahí:
- Con marcas, temas o lenguas en modo «Alguna», una etiqueta indica cuál de los valores que seleccionaste cumple ese resultado en concreto. Una palabra que cumpla dos muestra los dos.
- Con marcas secundarias —las de locuciones y combinaciones— enseña la locución concreta que coincide, con su marca al lado. Filtrando por Andalucía o Agricultura, almanta sale con «poner a almanta» (Agricultura), arvejona con «arvejona loca» (Andalucía) y barbado con «plantar de barbado» (Agricultura), sin abrir ninguna ficha.
- Y cuando expandes una búsqueda con los sinónimos que sugiere Iedra, cada resultado señala qué sinónimo ha provocado la coincidencia.
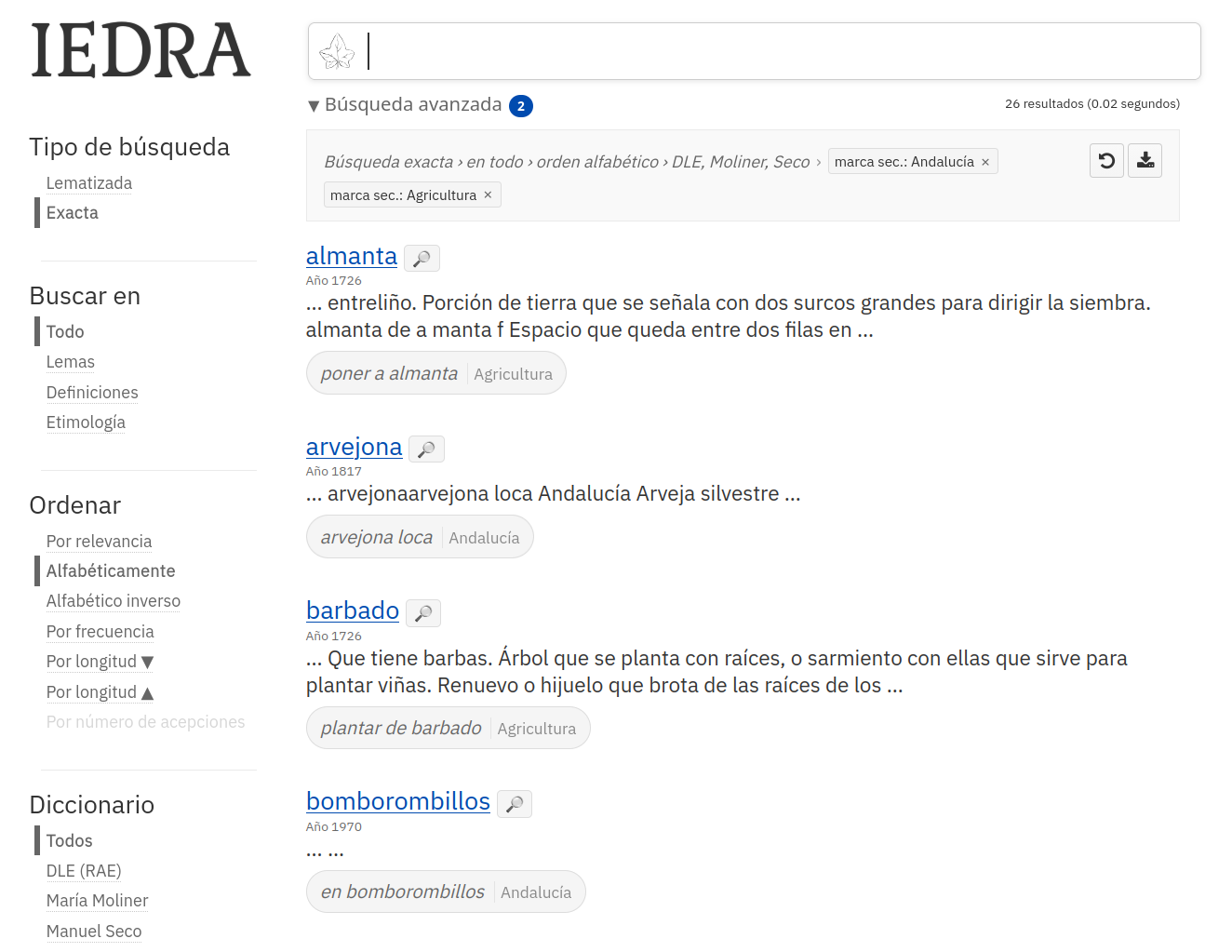 Con dos marcas de locución en modo «alguna», cada resultado enseña la locución que coincide y de cuál de las dos marcas viene.
Con dos marcas de locución en modo «alguna», cada resultado enseña la locución que coincide y de cuál de las dos marcas viene.
La idea nació de una sugerencia de un lector que arma crucigramas y rastreaba locuciones de un tipo concreto: tenía el filtro, pero no veía la locución sin entrar palabra por palabra. Ese paso de más ya no está.
Extractos solo cuando hay algo que resaltar
En la misma línea, han cambiado los extractos que acompañan a cada resultado. Cuando buscas por texto, cada palabra de la lista lleva debajo un fragmento de definición con los términos de la búsqueda resaltados: esa es su razón de aparecer, y se ve. El problema era el caso contrario: si filtrabas sin buscar texto —solo por sílabas, por marca, por lengua de origen—, no había nada que resaltar y el extracto caía a un recorte ciego de las definiciones, que mezclaba diccionarios y cortaba donde le pillaba. Ahora, si no hay coincidencia de texto que enseñar, no se muestra extracto: la razón de aparecer ya la cuentan las etiquetas de la sección anterior.
Una nota sobre los extractos: salen siempre del DLE o del Seco. El Moliner cuenta igualmente para la búsqueda —una palabra puede aparecer en los resultados porque tu búsqueda coincide con su definición del Moliner—, pero su texto no se reproduce en la lista. Entre el resaltado y las etiquetas, cada resultado enseña por qué está ahí, y solo eso.
Navegación por zonas en la ficha de palabra
Las fichas de palabras polisémicas son largas: un banco o un bote tienen acepciones, formas derivadas, marcas, sinónimos, antónimos, etimología, locuciones, combinaciones, rimas, anagramas… Para que la ficha sea navegable, ahora los bloques se agrupan en cuatro zonas y aparece una barra de cuatro botones justo bajo el título, uno por zona:
- Significado: definiciones, marcas, sinónimos, antónimos, locuciones.
- Origen: etimología (texto y diagrama), primera aparición, histórico de versiones del DLE.
- Forma: sílabas, acentuación, transcripción fonémica, anagramas, rimas.
- Contexto: tags temáticos, frecuencia, complejidad, refranero, Covarrubias.
Cada zona funciona como un punto de anclaje, así que se puede enlazar a cualquiera de ellas: elefante#origen lleva directamente al diagrama de etimología.
Índice global de herramientas en /explorar
Iedra ha ido acumulando páginas auxiliares —rimas, anagramas, complejidad, comparador entre versiones del DLE, temas, lenguas, locuciones, refranero, juegos…— que estaban repartidas por la navegación y a veces solo se llegaba a ellas por enlace. Ahora hay un índice único en /explorar que las recoge todas. La sección «Acerca de» (/about) también se ha puesto al día.
Si algo se ha desordenado, avisad.